目录
基础概念
Redis的运行
API的使用
基础概念
1.Redis是一种基于键值对的NoSQL数据库,Redis键值对中的值可以是由string、hash、list、set、zset(有序集合)、Bitmaps(位图)等多种数据结构和算法组成
2.Redis把所有的数据放在内存中,所有读写性能高,还会把数据用快照和日志的形式保存到硬盘上以防丢失
3.Redis用C语言实现,使用单线程架构
Redis的运行
1.因为Redis非常轻量,执行以下命令进行源码安装
1 | # 下载Redis指定版本的源码压缩包到当前目录 |
2.redis\src里的redis开头可执行脚本说明
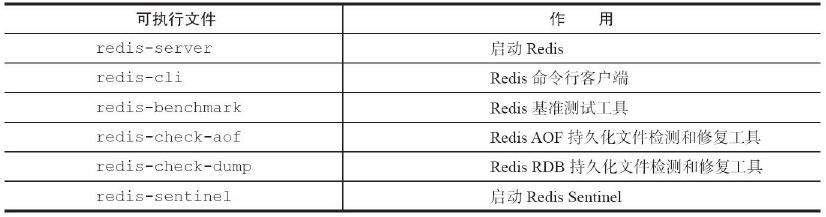
3.redis的启动方式
- 以默认配置启动:运行redis-server
- 以自定义配置启动:redis-server加上要修改配置名和值(可以是多对),没有设置的配置将使用默认配置
1
2redis-server --port 6380
# 表示以6380端口启动 - 以配置文件启动(常用):表示以该路径的.conf文件为配置启动
1
redis-server /opt/redis/redis.conf
4.连接redis服务器(注意要在启动redis-server的嵌套下才能连接)
交互式:即建立一个持续连接,然后直接在连接上多次使用命令
1
2
3
4
5输入:redis-cli -h 127.0.0.1 -p 6379
输出:127.0.0.1:6379> 输入:set hello world
输出:OK
输出:127.0.0.1:6379> 输入:get hello
输出:"world"命令式:即只执行一个命令后就关闭连接
1
2
3输入:redis-cli -h 127.0.0.1 -p 6379 get hello
输出:"world"-h默认127.0.0.1 -p默认6379
5.中断redis服务:断开与客户端的连接、持久化文件生成
1 | redis-cli shutdown nosave |
6.Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功能,例如不能对列表类型的一个元素做过期时间设置。
7.检验某节点是否正常工作
1 | redis-cli -h 127.0.0.1 -p 6379 ping |
8.检查某节点的主从关系
1 | redis-cli -h 127.0.0.1 -p 6379 info replication |
API的使用
1.全局命令
- 查看所有键(遍历,规模较大时禁用)
1
keys *
- 查看键总数(不用遍历,获取内置的键总数变量)
1
dbsize
- 查询键xx是否存在,存在为1,不存在为0
1
exits xx
- 删除键xx1和xx2(也可删除其它数据结构),会返回删除的数目
1
del xx1 xx2
- 设置键存活时间(默认秒),到时间会自动删除
1
expire xx 10
- 查询键剩余存活时间(-1是永不过期,-2是不存在该键)
1
ttl xx
- 查看键的数据结构(none表示键不存在)
1
type xx
2.redis里一样的数据结构可能也会有不同的内部编码,用下述命令来查看具体内部编码
1 | object encoding 键名 |
3.字符串:值可以是字符串、数字、二进制的视频音频(不超过512MB)
setex:建立键并设计秒级过期时间
setnx:键不存在才可以设置成功
setxx:键存在才可以设置成功
1
2
3setex 50 hello world
setnx hello world
setxx hello world批量操作
1
2mset 键1 值1 键2 值2
mget 键1 键2自增自减:
- 值不是整数,返回错误
- 值是整数,返回自增后的结果
- 键不存在,按照值为0自增,返回结果为1
1
2
3
4
5incr 键名
decr 键名
incrby 键名 数字
decrby 键名 数字
incrbyfloat 键名 浮点数
字符串内部编码类型(redis自动转换)
- int:8字节的长整数型(长度小于等于19并只含数字)
- emstr:小于等于39字节的字符串
- raw:大于39字节的字符串
4.常用方案MySql作存储层,Redis作缓存层。一般业务先去缓存层找,找不到再向MySql发出请求
5.哈希类型:哈希类型的键就相当于一个范围,范围里面的field:值就相当于一个键值对
- 建立哈希类型
1
hset 键名 filed名 值
- 获取某键的某个filed值
1
hget 键名 filed名
- 删除某键的某个filed
1
hdel 键名 filed名
- 获取某键的filed个数
1
hlen 键名
- 获得所有信息
1
2
3
4
5
6
# 获得所有filed名
hvals 键名
# 获得所有filed名和值
hgetall 键名 - 其他操作和字符串一样就是加个h(hmget、hmset等待)
- 内部编码有两种
- ziplist压缩列表:小规模数据时(元素个数少,值小)更节省内存
- hashttable哈希表:不满足使用ziplist时才使用
6.列表类型
- 列表里元素存储是有序的(即可以通过下标访问)、可重复的
- push、pop分别是添加删除元素
1
2
3
4
5
6
7
8
9lpush 列表名 xx1 xx2
lpop 列表名
lrem 列表名 count value
# rpush、rpop同理
# lrem会从列表删除count个值为value的元素
# count>0,从左到右,删除最多count个元素
# count<0,从右到左,删除最多count绝对值个元素。
# count=0,删除所有 - 在某元素前后插入元素
1
2
3linsert 列表名 before(after) xx1 xx2
# 在xx1前(后)插入xx2,会返回一个当前列表长度 - 获取某范围内的元素
1
2
3lrange 列表名 开始下标 结束下标
# 索引下标从左到右分别是0到N-1,但是从右到左分别是-1到-N。lrange中的结束选项包含了自身,即[开始下标,结束下标] - 获取某下标的元素
1
lindex 列表名 下标
- 获取列表长度
1
llen 列表名
- 修剪列表
1
2
3ltrim 列表名 开始下标 结束下标
# 只保留[开始下标,结束下标]的元素,其余全部删除 - 修改某个元素的值
1
lset 列表名 下标 newValue
- 阻塞式弹出
1
2
3
4
5blpop 列表1 列表2 timeout
brpop 列表1 列表2 timeout
# 若列表1、2都为空,等待timeout后还为空就返回,timeout=0表示一直阻塞等待
# 若列表1、2其中有一个能执行pop,立即返回 - 内部编码
- ziplist压缩列表:小规模数据时(元素个数少,值小)更节省内存
- linkedlist链表:不满足使用ziplist时才使用
7.集合类型
- 集合中的元素存储是无序的、不能有重复元素
- 添加元素
1
sadd key element
- 删除元素
1
srem key element
- 计算集合内元素个数
1
scard key
- 判断元素是否在集合中(在返回1,不在返回0)
1
sismember key element
- 随机从集合中返回元素
1
2
3srandmember key [count]
# count没给的话默认为1 - 随机从集合中弹出元素(会在集合中删除)
1
2
3spop key [count]
# Redis3.2后支持[count] - 获取所有元素
1
smembers key
- 求交集
1
sinter key [key ...]
- 求并集
1
suinon key [key ...]
- 求差集
1
sdiff key [key ...]
- 保存交、并、差集的结果
1
2
3
4
5
6sinterstore destination key [key ...]
suionstore destination key [key ...]
sdiffstore destination key [key ...]
# 例sinterstore user:1_2:inter user:1:follow user:2:follow
# 是将user:1:follow和user:2:follow两个集合的交集结果保存在user:1_2:inter中 - 内部编码
- intset整数集合表:小规模数据且都为整数时(元素个数少,值小)更节省内存
- hashtable哈希表:不满足使用intset时才使用
8.有序集合类型
- 有序、不能有重复元素,给每个元素设置一个分数(score)作为排序的依据,分数可以重复
- 添加成员(添加时要设置好分数)
1
zadd key score member [score member ...]
- 删除成员
1
zrem key member [member ...]
- 计算含有的成员个数
1
zcard key
- 计算某成员的分数(成员不存在就返回nil)
1
zscore key member
- 计算成员的排名
1
2
3
4zrank key member
zrevrank key member
# zrank是升序,zrevrank是降序 - 增加成员分数
1
2
3
4
5zincrby key increment member
# 例输入zincrby user:ranking 9 tom 返回"260"
# 表示
给user有序集合里的tom增加了9分,其分数变为260分 - 返回指定排名范围的成员
1
2
3
4zrange key start end [withscores]
zrevrange key start end [withscores]
# 如果加上withscores关键字还会一同返回分数 - 删除指定排名范围内的成员(升序)
1
zremrangebyrank key start end
- 返回指定分数范围内的成员个数
1
zcount key min max
- 删除指定分数范围内的成员
1
zremrangebyscore key min max
- 交集
1
zinterstore destination numkeys key [key ...] [weights weight [weight ...]][aggregate sum|min|max]
- 并集destination:交集计算结果保存到这个键
1
zunionstore destination numkeys key [key ...] [weights weight [weight ...]][aggregate sum|min|max]
numkeys:需要做交集计算键的个数
key[key…]:需要做交集计算的键
weights weight[weight…]:每个键的权重,在做交集计算时,每个键中的每个member会将自己分数乘以这个权重,每个键的权重默认是1
aggregate sum|min|max:计算成员交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做汇总,默认值是sum
- 内部编码
- ziplist压缩列表:小规模数据时(元素个数少,值小)更节省内存
- skiplist跳跃表:不满足使用ziplist时才使用
键管理
1.单个键管理
- 键重命名
1
2
3
4rename key newkey
# 若newkey已存在,会先删除newkey,再重命名
# 想避免上述情况用renamenx key newkey,只有newkey不存在才会重命名成功 - 随机返回一个键的名字
1
randomkey
- 去除键的过期时间
1
2
3persist key
# set键的时候也会自动去除键的过期时间 - 迁移键(迁移数据)
- 在Redis内部数据库之间迁移
1
2
3move key db
# 把指定键从源数据库迁移到指定数据库 - 在不同的Redis实例之间进行数据迁移(例两个客户端)还有一种方法migrate(实际上是集成了dump、restore、del)
1
2
3
4
5
6
7
8源客户端运行:
dump key
目标客户端运行:
restore key ttl value
# ttl表示设置过期时间,ttl=0表示不过期
# value是源客户端运行dump命令后返回的字符串1
2
3
4
5
6
7
8
9
10migrate host port key|"" destination-db timeout [copy] [replace] [keys key [key ...]]
# host:目标Redis的IP地址。
# port:目标Redis的端口。
# key|"":在Redis3.0.6版本之前,migrate只支持迁移一个键,所以此处是要迁移的键,但Redis3.0.6版本之后支持迁移多个键,如果当前需要迁移多个键,此处为空字符串""
# destination-db:目标Redis的数据库索引,例如要迁移到0号数据库,这里就写0
# timeout:迁移的超时时间(单位为毫秒)
# [copy]:如果添加此选项,迁移后并不删除源键
# [replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖
# [keys key[key...]]:迁移多个键,例如要迁移key1、key2、key3,此处填写“keys key1 key2key3”迁移单个键的话这次为空
- 在Redis内部数据库之间迁移
2.遍历键的操作
- 全量遍历,根据匹配式返回符合要求的键
1
2
3
4
5
6keys pattern
# pattern = * 时表示返回所有键
# *代表匹配任意字符;·代表匹配一个字符;[]代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配1到10的任意数字;\x用来做转义,例如要匹配星号、问号需要进行转义
# 例keys [j,r]edis
# 会返回名为redis和jedis的键 - 渐进式遍历,为解决全量遍历遇到阻塞诞生的,相当于一次只扫描一部分,多次扫描才完成hscan、sscan、zscan分别是哈希类型、集合类型、有序集合类型的扫描遍历命令
1
2
3
4
5
6
7
8
9scan cursor [match pattern] [count number]
# cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束
# match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像
# count number是可选参数,它的作用是表明每次要遍历的键个数,默认
值是10,此参数可以适当增大。
# 例子 输入scan 0
# 返回1) "6"和2) 1) "w".....(“1)”里面是游标,“2)”里面是当前部分遍历返回的数据)
# 然后第二次就要输入scan 6 ...依次类推
数据库管理(开发环境少用)
1.Redis默认配置中是有16个数据库,序号为0到15
1 | 127.0.0.1:6379> 表示0号数据库 |
2.切换数据库
1 | select dbIndex |
3.清除数据库
1 | # 清除当前数据库 |
4.Redis是单线程的。如果使用多个数据库,那么这些数据库仍然是使用一个CPU,彼此之间还是会受到影响的。
- 多数据库的使用方式,会让调试和运维不同业务的数据库变的困难,假如有一个慢查询存在,依然会影响其他数据库,这样会使得别的业务方定位问题非常的困难。
- 部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候
来回切换数字形式的数据库,很容易弄乱。 - 如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此用端口来做区分
持久化
1.Redis持久化有两种:
- RDB:把当前进程数据生成快照保存到硬盘,分为手动触发和自动触发
- AOF:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的,实时持久化
2.RDB的触发机制
- 手动触发
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,不建议使用
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短(Redis内部默认这种方式)
- 自动触发
- 使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave
- 从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时,也会自动触发save操作。
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave
3.RDB的bgsave执行流程
图2
- 执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回
- 父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞
- 父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,从这里起保存由子进程负责,父进程可以继续去执行其他命令
- 子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后
对原有文件进行原子替换 - 进程发送信号给父进程表示完成
4.RDB的优缺点
- 优点
- RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景,比如用于灾难恢复
- Redis加载RDB恢复数据远快于AOF
- 缺点
- RDB方式数据没办法做到实时持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高
- RDB文件使用特定二进制格式保存,有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题
5.实时持久化的AOF
- 开启AOF服务功能
1
appendonly yes
- AOF工作流程:
- 命令写入append:有写入命令时,将该记录放到AOF缓冲中
- 文件同步sync:将AOF缓冲中的记录写入到AOF文件
- always:每次写入都同步到AOF文件中(fsync产生阻塞,直到单个文件完全同步)
- no:同步周期由操作系统决定(一般30s)(write写入缓存就就返回,同步时间取决于系统什么时候调度完成缓存中的任务)
- everysec:每秒同步一次,建议采用(write)
- 文件重写rewrite:因为AOF文件会越来越大,所有需要定期重新生成AOF文件并在该过程进行一定压缩(将已经失效的写命令和数据删掉,将一些可合并的写命令合并)
- 重启加载load:加载AOF文件恢复数据
- AOF命令写入缓冲区的内容直接是文本协议格式
- 原因1:直接采用协议格式,避免了二次处理开销,且文本协议便于修改
- 原因2:如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载
6.Redis启动时的加载顺序
- 若开启AOF,则优先加载AOF文件,不存在AOF文件才去加载RDB文件
- 若未开启AOF,则优先加载RDB文件,若RDB文件不存在直接启动
7.fork的优化,当Redis做RDB或AOF重写时,一个必不可少的操作就是执行fork操作创建子进程,虽然子进程不需要拷贝父进程的物理内存空间,但也会复制父进程的空间内存页表
- 优先使用物理机或者高效支持fork操作的虚拟化技术,避免使用Xen
- 控制Redis实例最大可用内存,因为fork耗时跟内存量成正比
- 合理配置Linux内存分配策略,避免物理内存不足导致fork失败
- 降低fork操作的频率,如适度放宽AOF自动触发时机
8.持久化阻塞主线程场景有
- fork阻塞,跟内存量和系统有关
- AOF追加阻塞,说明硬盘资源紧张
9.单机下部署多个实例时(因为Redis是单线程,部署多个实例才能有效利用多核),为了防止出现多个子进程执行重写操作,应该做隔离控制,避免CPU和IO资源竞争
复制
1.Redis通过复制功能实现主节点的多个副本。从节点可灵活地通过slaveof命令建立或断开复制流程
- 主节点的数据更新时,从节点会自动获取,建立复制后主节点和从节点之间有一个长连接,并彼此发送心跳命令
- 从节点默认只读模式,这个配置一般不能修改,因为主节点无法感知从节点数据的变化,直接修改从节点后会导致主从数据不一致
- 从节点可以复制另一个从节点,实现一层层向下的复制流,复制的分为:全量复制和部分复制
2.主、从节点本质都是一个独立的Redis进程
3.Redis为了保证高性能复制过程是异步的,写命令处理完后直接返回给客户端,不等待从节点复制完成。因此从节点数据集会有延迟情况
4.主节点无法正常启动后,需要从节点人为干预执行slaveof no one晋升为新的主节点,再让其他从节点与其建立连接
哨兵Redis Sentinel
1.Redis Sentinel是一个分布式架构,其中包含若干个Sentinel节点和Redis数据节点
- 每个Sentinel节点会对数据节点和其余Sentinel节点进行监控
- 当它发现节点不可达时,会对节点做下线标识。
- 如果被下线标识的是主节点,它还会和其他Sentinel节点进行“协商”,当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方
2.在Redis Sentinel结构中,客户端在初始化的时候连接的是Sentinel节点集合,由Sentinel节点集合告知主节点信息
- Sentinel节点集合是由若干个Sentinel节点组成的,这样即使个别Sentinel节点不可用,整个Sentinel节点集合依然是健壮的
- Sentinel节点本身就是独立的Redis节点,只不过它们有一些特殊,它们不存储数据,只支持部分命令
3.启动哨兵节点有两种方式(效果一样)
1 | redis-server redis-sentinel-26379.conf --sentinel |
4.查看哨兵节点信息
1 | redis-cli -h 127.0.0.1 -p 26379 info sentinel |
5.发送故障时,哨兵模式的解决过程
- 选出合适从节点
- 晋升选出的从节点为主节点。
- 命令其余从节点复制新的主节点。
- 等待原主节点恢复后命令它去复制新的主节点
6.sentinel的API
- 显示被监控的所有主节点的状态和信息
1
sentinel masters
- 显示指定主节点的状态和信息
1
sentinel master<master name>
- 显示指定主节点的从节点的状态和信息
1
sentinel slaves<master name>
- 显示指定主节点的sentinel节点的状态和信息
1
sentinel sentinels<master name>
- 返回指定
主节点的IP地址和端口 1
sentinel get-master-addr-by-name<master name>
- 强制对某主节点立即进行故障转移
1
sentinel failover<master name>
- 检查一遍sentinel节点正常个数是否达到配置文件设置的
,也即是否满足故障转移的条件 1
sentinel ckquorum<master name>
- 将当前的Sentinel节点的配置强制刷到磁盘上(当外部原因(例如磁盘损坏)造成配置文件损坏或者丢失时,这个命令很有用)
1
sentinel flushconfig
- 取消当前sentinel节点对主节点的监控
1
sentinel remove<master name>
- 该sentinel节点建立对主节点的监控(和配置一模一样)
1
sentinel monitor<master name><ip><port><quorum>
- 更新当前sentinel节点的配置
1
sentinel set <param> <value>
Redis配置文件详解
1.主要配置
1 | port 6379 //指明使用端口 |
2.哨兵节点配置
1 | # 代表该sentinel节点需要监控127.0.0.1:6379这个主节点,2代表判断主节点失败至少需要2个Sentinel节点同意,mymaster是给主节点起的别名(即master name) |